Fantasyalive
Limp Gawd
- Joined
- Nov 3, 2010
- Messages
- 274
Interesting, thats 3 reviews now with similiar benches.
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
Interesting, thats 3 reviews now with similiar benches.
But can it run Quake 3?
")

Yes... 8 instances, at 10fps per core... Will that be fast enough...
Another preliminary (read FAKE) bench, and I quote:
Green bar is FX8120
This is without right drivers and BIOS.
Could be completely different after AMD releases additional drivers.
There was also a slight TeamView overhead.
Ohh man, this made me LOL!!!!
Its not even performing badly. The graphs are horrid. Most of the numbers are quite close.
lmao!
this this this, I have a sandy bridge chip and won't be buying this. However these results aren't bad if you look at the numbers. There might be some issue with the cinebench but otherwise not bad at all, especially if they price it right.
hahahaha.
that got me too. Her laugh is contagious.
My impression of an intel fanboys impression of an AMD fanboy:
seriously, did you look at the graphs? The scaling is all over the place to show bigger gaps between performance rather than the hard numbers
Enjoy your 8 Athlon 64 cores.Exactly what Intel would want.
Ohh man, this made me LOL!!!!
hehe nice video, reminds me of the Hitler reacts to fermi video.
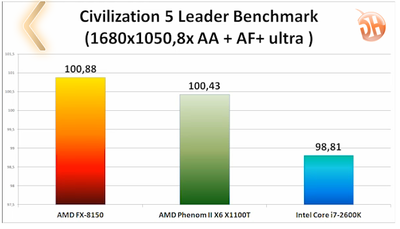
it's funny, i don't see the AMD fanboys bitching about this graph.
WHOAAAA. Look at that huge gap. look how slow the 2600k is !!

http://comments.gmane.org/gmane.linux.kernel/1170214Actually, we already have such an issue known for Bulldozer, and NO bench-marked system has the patch installed!
The shared L1 cache is causing cross invalidations across threads so that the prefetch data is incorrect in too many cases and data must be fetched again. The fix is a "simple" memory alignment and (possible)tagging system in the kernel of Windows/Linux.
I reviewed the code for the Linux patch and was astonished by just how little I know of the Linux kernel... lol! In any event, it could easily cost 10% in terms of single threaded performance, possibly more than double that in multi-threaded loads on the same module due to the increased contention and randomness of accesses.
Not sure if ordained reviewers have been given access to the MS patch, but I'd imagine (and hope) so! Last I saw, the Linux kernel patch was still being worked on by AMD (publicly) and Linus was showing some distaste for the method used to address the issue. One comment questioned the performance cost but had received no replies... but you don't go re-working kernel memory mapping for anything less than 5-10%... just not worth it!
Avi Kivity [Red Hat Linux]: Out of curiosity, what's the performance impact if the workaround is not enabled?
Borislav Petkov [AMD]: Up to 3% for a CPU-intensive style benchmark, and it can vary highly in a microbenchmark depending on workload and compiler.
I'll be happy if BD can get a 10% improvement via software (OS patches) but in that linux kernel patch discussion (good read) the AMD engineer estimates the improvement to be around 3%.
Argh. This is a small disaster, you know that, right? Suddenly we have
user-visible allocation changes depending on which CPU you are running
on. I just hope that the address-space randomization has caught all
the code that depended on specific layouts.
And even with ASLR, I wouldn't be surprised if there are binaries out
there that "know" that they get dense virtual memory when they do
back-to-back allocations, even when they don't pass in the address
explicitly.
How much testing has AMD done with this change and various legacy
Linux distros? The 32-bit case in particular makes me nervous, that's
where I'd expect a higher likelihood of binaries that depend on the
layout.
You guys do realize that we had to disable ASLR on many machines?
So at a MINIMUM, I would say that this is acceptable only when the
process doing the allocation hasn't got ASLR disabled.
....
Anyway, I seriously think that this patch is completely unacceptable
in this form, and is quite possibly going to break real applications.
Maybe most of the applications that had problems with ASLR only had
trouble with anonymous memory, and the fact that you only do this for
file mappings might mean that it's ok. But I'd be really worried.
Changing address space layout is not a small decision.
it's funny, i don't see the AMD fanboys bitching about this graph.
WHOAAAA. Look at that huge gap. look how slow the 2600k is !! It's slower by 200 frames/sec !!#!&^%*%&$^
LoL another idiot reviewer who can't make good cpu test in games.
Just by looking at 1100T so near to 2600K it should be obvious they tested places where GPU was limiting factor.
Yeah, buying the best processor for the money makes me a fanboy.
hehe nice video, reminds me of the Hitler reacts to fermi video.
Funny, you are the only one bitching about it.
I understood the 3% as the performance penalty you pay when you install the patch. Not all code causes the aliasing issue, but by installing the patch you'll affect the whole stack. Affected code will run at normal speed.
The issue doesn't seem to be very small according to Linus :
On Wed, Jul 27, 2011 at 11:57:45AM -0400, Avi Kivity wrote:
> Out of curiosity, what's the performance impact if the workaround is
> not enabled?
Borislav Petkov (AMD) wrote:
Up to 3% for a CPU-intensive style benchmark, and it can vary highly in
a microbenchmark depending on workload and compiler.